Various ways to implement a daemon that pings remote hosts.
 dblume
Update README.md for change from master to main
21e88e5 @ 2021-11-19 08:27:21
dblume
Update README.md for change from master to main
21e88e5 @ 2021-11-19 08:27:21
| images | Add a version that uses a lock instead of a queue. | 2019-07-06 11:32:09 |
|---|---|---|
| LICENSE.txt | first commit. | 2019-07-05 20:08:07 |
| README.md | Update README.md for change from master to main | 2021-11-19 08:27:21 |
| long_lived_looping_locked_workers.py | Add type hints. | 2020-12-30 23:04:36 |
| long_lived_looping_workers.py | Add type hints. | 2020-12-30 23:04:36 |
| long_lived_worker_queue.py | Add type hints. | 2020-12-30 23:04:36 |
| short_lived_workers.py | Add type hints. | 2020-12-30 23:04:36 |
python_pinger
These are different approaches to how one might implement a daemon to repeatedly ping multiple hosts to see if the network is up.
Aside: disown vs nohup
Once you have such a daemon, you could call it with nohup or disown it after running it in the background. Here's a good description of the subtle differences.
Using disown
mydaemon.py &
disown [jobid]
Using nohup
nohup mydaemon.py &
Single Threaded
This is the most naive implementation. For each ping host, the main process thread pings them one at a time, and prints any changes.
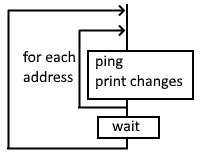
The code for such a loop might look like this:
# "results" is a dict of ip_address -> last ping result
for address in results.keys():
result = ping(address)
if result != results[address]:
log(f'{time.strftime("%Y-%m-%d %H:%M:%S", now)} {address} {result}')
results[address] = result
time.sleep(delay)
Logs go to a logfile, and example output looks like this:
2019-07-06 11:23:20 192.168.1.1 UP
2019-07-06 11:23:20 192.168.1.12 UP
2019-07-06 11:23:29 192.168.1.12 DOWN
2019-07-06 11:23:39 192.168.1.12 UP
Upsides
Really simple code.
Downsides
Since the pings are serialized, one long timeout from one host could affect detecting a problem at another host.
Long Lived Workers Consuming from a Queue
Raymond Hettinger's PyBay 2018 Keynote uses the queue module to send data between threads, so I thought I'd make a version of the pinger that did the same.
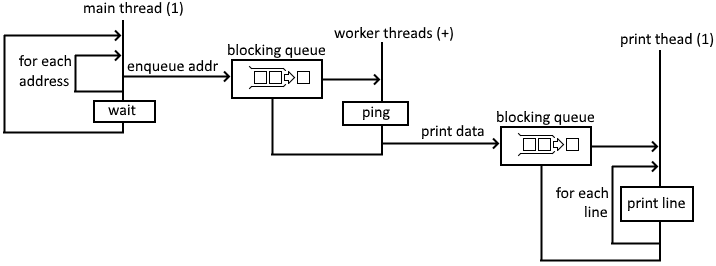
The main thread sends an address to a queue that the worker threads wait upon.
See the source: long_lived_worker_queue.py
Upsides
Multi-threaded ping calls won't block each other.
Downsides
The ping tasks read from, and write to a shared dictionary, so they need to serialize that access.
Short Lived Workers
How about we don't keep the workers around, and only spawn them when there's something to do? That way, we won't waste memory when there's nothing going on. The main thread passes the address to the workers when they're constructed.
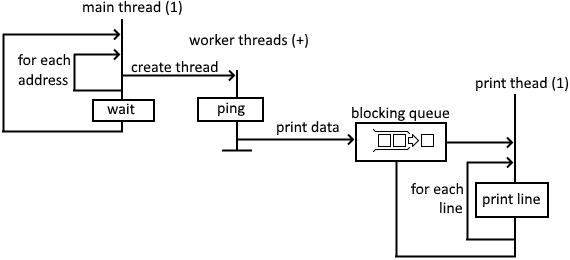
See the source: short_lived_workers.py
Upsides
The worker tasks aren't in memory if they're not doing anything. So usually a smaller memory profile.
Downsides
The ping tasks still read from, and write to that shared dictionary, so they serialize that access.
Long Lived Looping Workers
I saved the best for last. The only thing the main thread does is bring the workers and the print manager to life. The workers each independently do their own loop: ping, compare, print, and wait.
Since the process thread doesn't have anything to do after spawning the workers, it can be one of the workers.
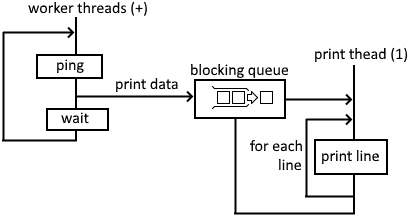
See the source: long_lived_looping_workers.py
Upsides
No more race conditions! The worker threads mind their own business.
Downsides
The worker threads remain in memory.
Long Lived Looping Locked Workers
That was fun using only the synchronized queue class and no locks. But now that we've got the long lived looping workers that don't need their own queue, let's replace the print manager with a threading lock.
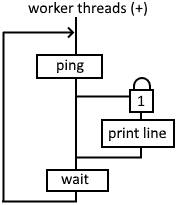
See the source: long_lived_looping_locked_workers.py
Upsides
Got rid of the entire printer thread.
Downsides
Uses a lock, which in more complex applications with multiple locks becomes difficult to reason about.
Is it any good?
Yes.
Licence
This software uses the MIT license.